根据ZOL中关村在线评测,1月底我们对英特尔酷睿Ultra X9 388H处理器进行了详细评测,其CPU性能、能效以及GPU性能表现给我们留下了深刻印象。但其实除了CPU和GPU性能、能效大幅提升之外,第三代酷睿Ultra处理器在AI算力方面也是得到了显著提升。其CPU+NPU+GPU算力达到了180TOPS,其中GPU算力达到了120TOPS,而NPU虽然只提升了2TOPS,但是其矩阵引擎规模变大之后,实际计算效率远比纸面的2TOPS更高。
那么酷睿Ultra X9 388H在大语言模型应用中的表现如何?下面我们就一起来测试一下。 下方这张GIF图是1倍速录制的酷睿Ultra X9 388H在跑DeepSeek-R1-14B时的速度,基本上满足了本地使用的速度需求。不过也能看出,14B应该是这颗处理器本地部署和使用稠密AI大语言模型的上限了,如果想使用更大参数量的大模型,那么就需要部署MoE混合模型,这样才能保持生成速度。
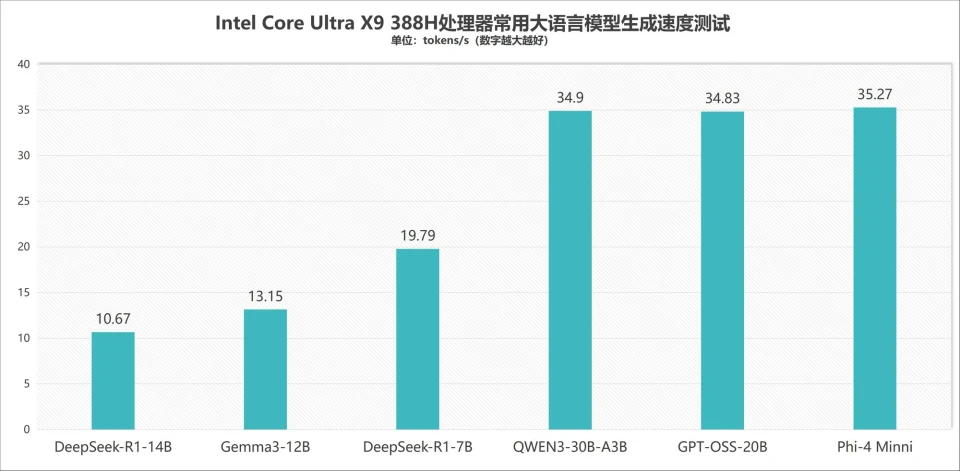
我们测试了六款常用大语言模型,DeepSeek-R1-14B生成速度为10.67 tokens/s,Gemma 3-12B生成速度为13.15 tokens/s,DeepSeek-R1-7B生成速度为19.79 tokens/s,Qwen 3-30B-A3B混合专家模型生成速度为34.9 tokens/s,GPT-OSS-20B生成速度为34.83 tokens/s,Phi-4 Mini生成速度为35.27 tokens/s。
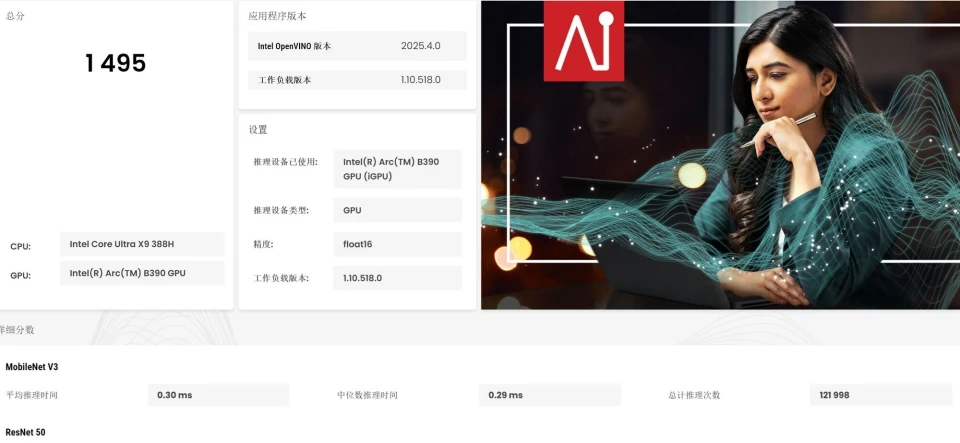
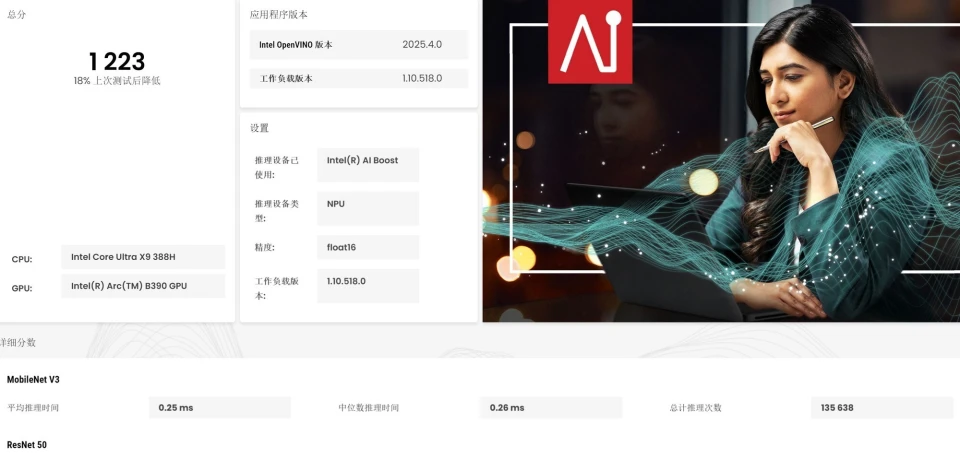
从测试结果来看,酷睿Ultra X9 388H凭借锐炫B390核显性能提升,可以流畅运行14B及以下参数量的稠密模型,也可以通过部署MoE混合专家模型,来使用更大参数量的模型,不过激活参数量自然是最好不要超过14B,否则速度会比较慢。 最后还是附上之前评测中的理论测试情况,具体如下: 首先通过UL Procyon对其GPU和NPU算力进行了测算,可以看到锐炫B390核显的GPU Float16算力评分达到1495,相对于上一代的800+提升了近700分;而NPU算力评分达到1223,相对于上一代900+的评分提升了300多分,因此酷睿Ultra X9 388H在GPU和NPU算力上分别提升了约78%和32%!
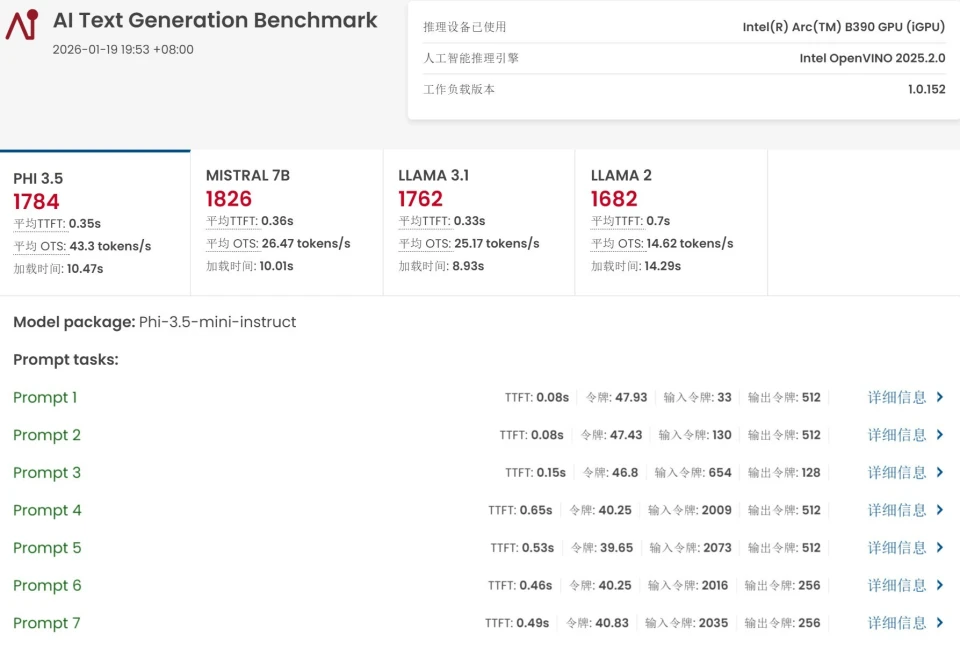
上一代核显受算力和显存不足的制约,无法完成UL Procyon的AI大语言模型生成测试,而酷睿Ultra X9 388H不仅能够顺利完成,并且在PHI 3.5、MISTRAL 7B、LLAMA 3.1、LLAMA 2四款大语言模型测试中,生成速度分别达到了43.3 tokens/s、28.47tokens/s、25.17tokens/s以及14.02tokens/s。
通过本地AI大语言模型测试可以看到,得益于GPU AI算力的升级,英特尔酷睿Ultra X9 388H是完全可以在本地部署并流畅使用14B及以下参数量AI大语言模型的硬件平台,同时还可以通过MoE模型来使用更大参数量的混合专家模型,基本能够满足本地化部署和使用AI大模型的需求。 |

手机APP
手机版

官方微信